Appendix F — Ensemble and distillation
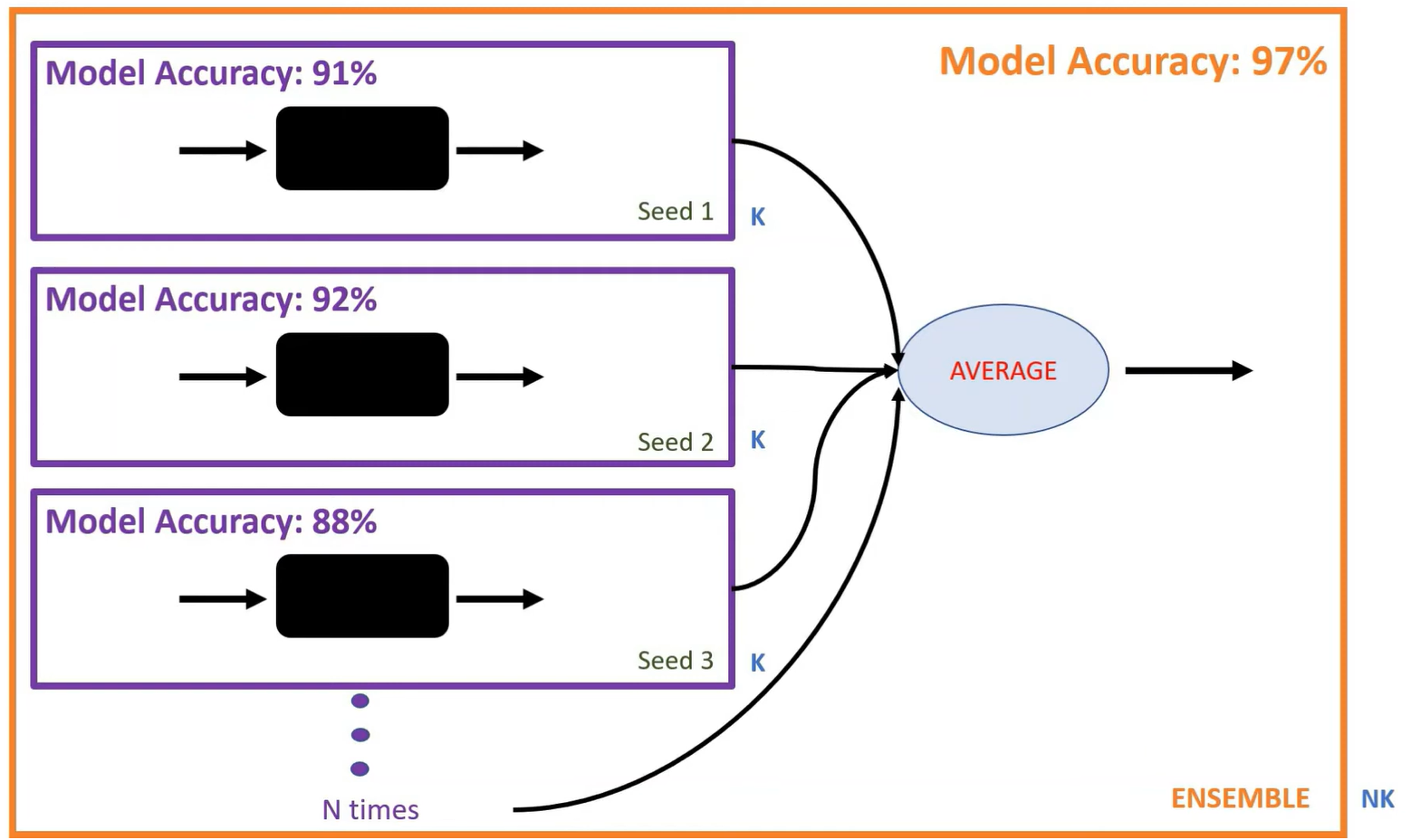
If one model has \(k\) parameters, the ensemble model will have \(Nk\) parameters and will run very slow.
Knowledge distillation is one way to overcome this by training another model with maybe just \(k\) parameters that is as good as the \(Nk\) model.
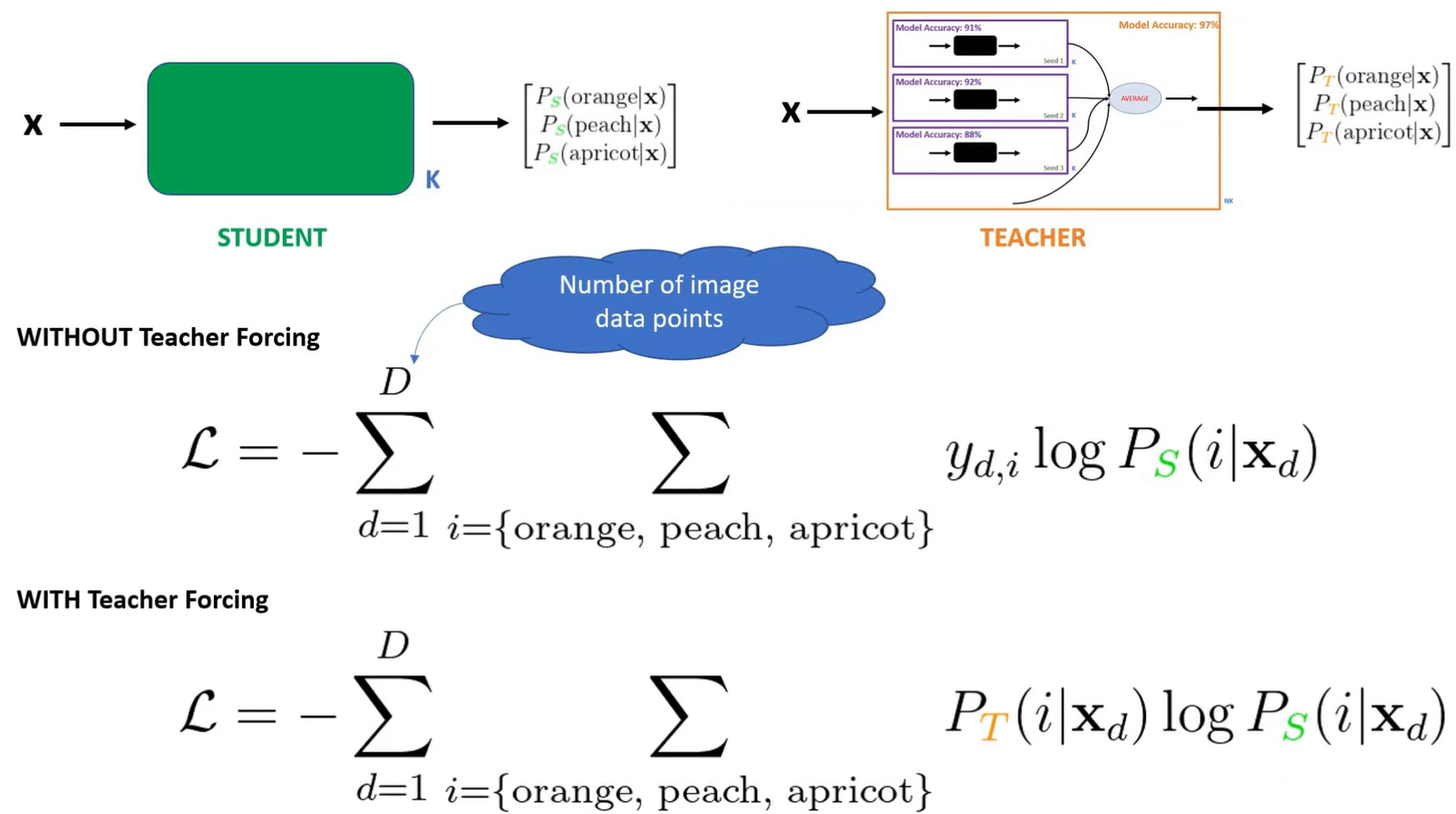
It’s called “knowledge distillation” because the larger teacher model’s “knowledge” is being condensed (like a distillate) into a smaller student model. The student model is trained using softened outputs from the teacher model (which means probabilities rather than the hard 0/1 labels).