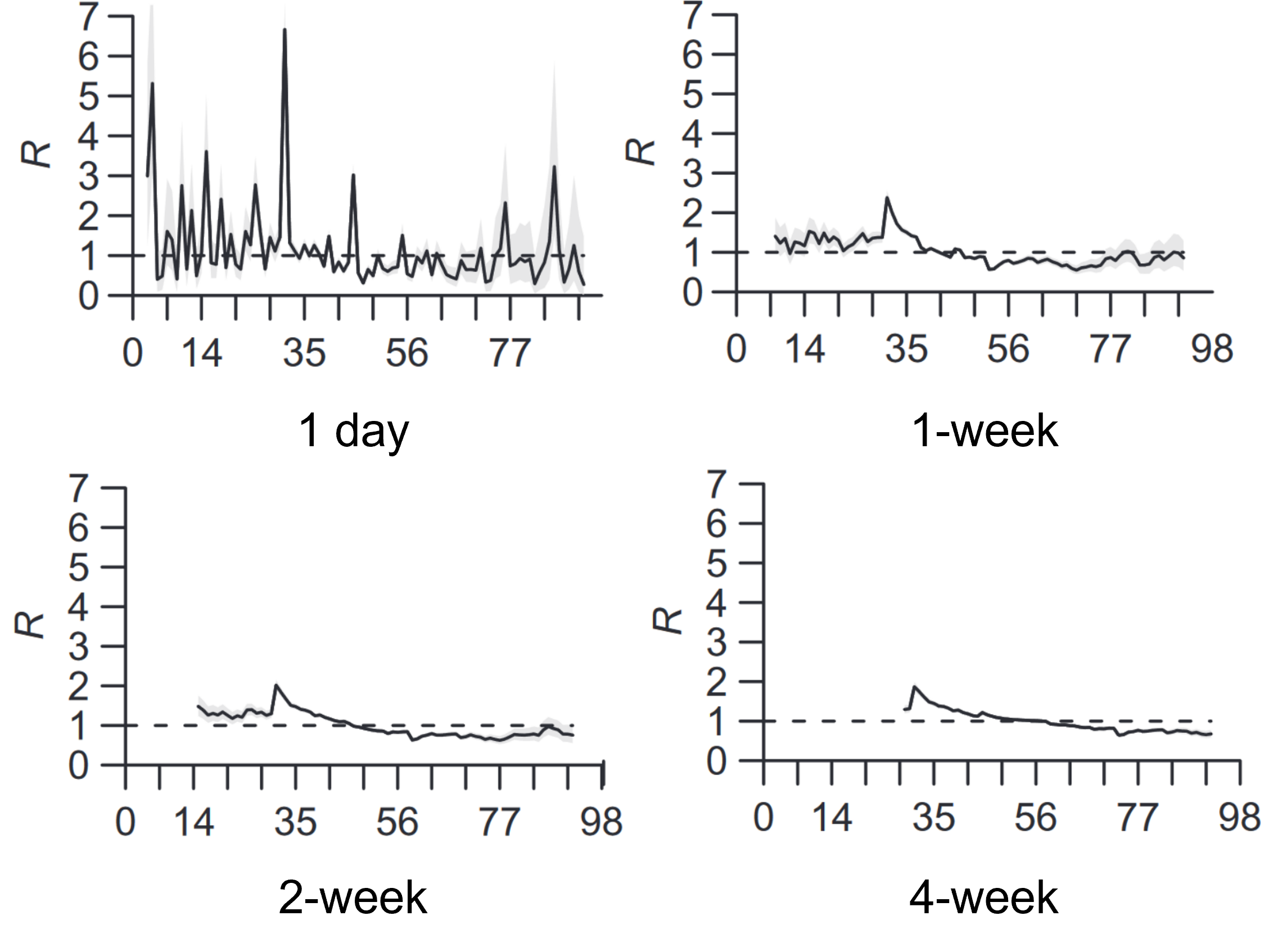
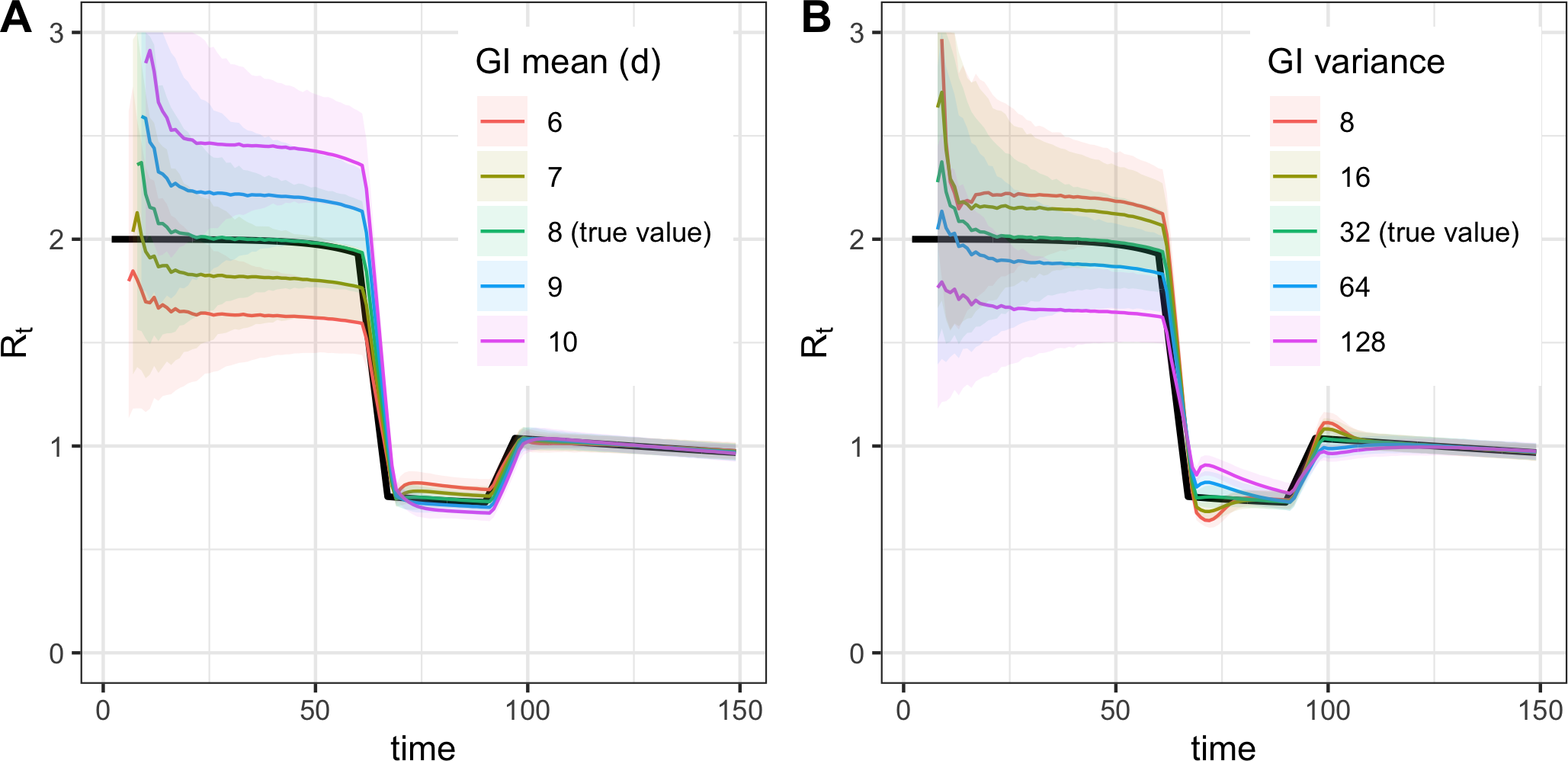
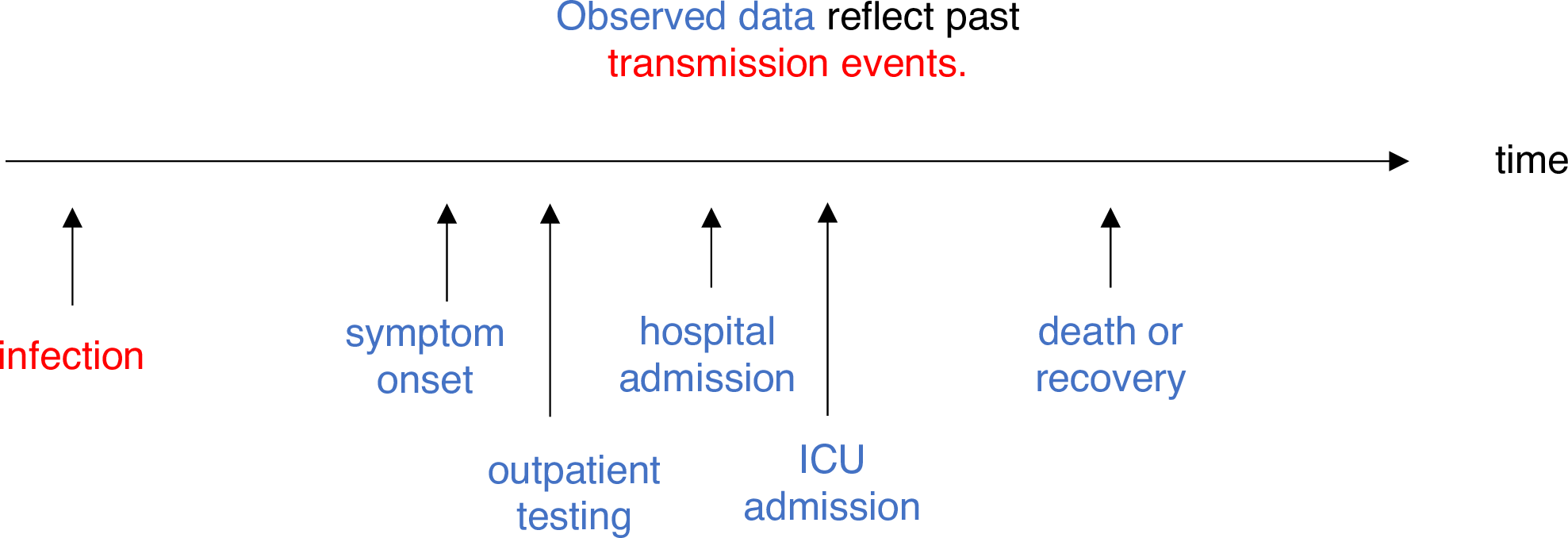
wtSteps = {
// ═══════════════════════════════════════════════════════════════════════
// Hover stroke is now proportional (w * 42 or p * 44, with small floors)
// so a hovered arc's thickness still reflects its magnitude, just bigger
// than its non-hovered scale (w * 28, p * 30). SVG text sizes and chip /
// bubble dimensions have been bumped so everything reads at a glance.
// ═══════════════════════════════════════════════════════════════════════
// ── Outbreak: 1-2-3-2-1 (9 cases) ──
const perDay = [1, 2, 3, 2, 1];
const cases = [];
let nxt = 1;
for (let d = 0; d < perDay.length; d++)
for (let k = 0; k < perDay[d]; k++)
cases.push({ id: nxt++, day: d + 1, slot: k, total: perDay[d] });
const N = cases.length, T = perDay.length;
const SMAX = Math.max(T + 3, 8);
// ── Discretised gamma weights ──
const weights = new Float64Array(SMAX + 1);
function updW(m, sd) {
const shape = (m * m) / (sd * sd);
const scale = (sd * sd) / m;
let tot = 0;
weights[0] = 0;
for (let s = 1; s <= SMAX; s++) {
weights[s] = Math.pow(s, shape - 1) * Math.exp(-s / scale);
tot += weights[s];
}
if (tot > 0) for (let s = 1; s <= SMAX; s++) weights[s] /= tot;
}
const computeDenom = i => {
const di = cases[i].day;
let D = 0;
for (let k = 0; k < N; k++) {
if (k === i) continue;
const g = di - cases[k].day;
if (g > 0 && g <= SMAX) D += weights[g];
}
return D;
};
const computePij = (i, j) => {
const g = cases[i].day - cases[j].day;
if (g <= 0 || g > SMAX) return 0;
const D = computeDenom(i);
return D > 0 ? weights[g] / D : 0;
};
const computeRj = j => {
let r = 0;
for (let i = 0; i < N; i++)
if (cases[i].day > cases[j].day) r += computePij(i, j);
return r;
};
// ── State ──
// Click-committed state (works on desktop + mobile via tap)
let selI = 4; // Panel 1 i
let selJ1 = null; // Panel 1 j, set by tap on an earlier case (toggle)
let selJ2 = 1; // Panel 2 j
let stickI2 = null; // Panel 2 isolated i, set by tap on a later case (toggle)
// Hover-only transients (desktop only; ignored on touch devices)
let hoverJ = null;
let hoverI2 = null;
// ── Layout ──
const W = 900;
const NODE_R = 22;
const netM = { top: 62, right: 54, bottom: 54, left: 54 };
const netPlotW = W - netM.left - netM.right;
const xSp = netPlotW / (T - 1);
const slotOffsets = {
1: [0],
2: [-30, 30],
3: [-58, 0, 58]
};
const slotOff = c => slotOffsets[c.total][c.slot];
const nodePos = (c, H) => ({
x: netM.left + (c.day - 1) * xSp,
y: netM.top + (H - netM.top - netM.bottom) / 2 + slotOff(c)
});
function arcGeom(pi, pj, gap) {
const lift = Math.min(230, 150 + gap * 28);
const mx = (pi.x + pj.x) / 2;
const cy = (pi.y + pj.y) / 2 - lift;
const py = (pi.y + pj.y) / 2 - lift / 2;
return { d: `M ${pj.x} ${pj.y} Q ${mx} ${cy} ${pi.x} ${pi.y}`, px: mx, py };
}
const pairs = [];
for (let i = 0; i < N; i++)
for (let j = 0; j < N; j++)
if (cases[j].day < cases[i].day) pairs.push({ i, j });
const subD = n => String(n).split("").map(d => "₀₁₂₃₄₅₆₇₈₉"[+d]).join("");
const SUM_SYM = "Σₖ≠ᵢ wₜᵢ₋ₜₖ";
// ── Wrapper & styles ──
const wrapper = document.createElement("div");
wrapper.className = "wtsteps-wrap";
wrapper.style.cssText = "font-family:system-ui,-apple-system,sans-serif;max-width:960px;margin:0 auto;";
wrapper.appendChild(injectStyle());
const style = document.createElement("style");
style.textContent = `
.wtsteps-wrap { color:#1e293b; }
.wtsteps-wrap .panel { border:1px solid #e2e8f0; border-radius:12px;
margin-bottom:14px; overflow:hidden; background:#fff;
box-shadow:0 1px 3px rgba(15,23,42,0.05); }
.wtsteps-wrap .panel-head { display:flex; align-items:center; gap:12px;
padding:12px 20px; border-bottom:1px solid #e2e8f0;
background:var(--bg); flex-wrap:wrap; }
.wtsteps-wrap .badge { background:var(--c); color:#fff; padding:4px 12px;
border-radius:14px; font-weight:700; font-size:12px;
letter-spacing:0.5px; text-transform:uppercase; white-space:nowrap; }
.wtsteps-wrap .pname { font-weight:700; font-size:15px; color:#1e293b;
white-space:nowrap; }
.wtsteps-wrap .pformula { font-family:'SF Mono',Menlo,Consolas,monospace;
color:#475569; font-size:14px; margin-left:auto; }
.wtsteps-wrap .panel.step1 { --c:#2563eb; --bg:#eff6ff; }
.wtsteps-wrap .panel.step2 { --c:#059669; --bg:#ecfdf5; }
.wtsteps-wrap .panel.step3 { --c:#d97706; --bg:#fffbeb; }
.wtsteps-wrap svg { display:block; width:100%; height:auto; }
.wtsteps-wrap .node-grp { cursor:pointer; }
.wtsteps-wrap .node-grp circle { transition: stroke-width 0.12s; }
.wtsteps-wrap .node-grp:hover circle { stroke-width: 3.4; }
.wtsteps-wrap .hint { font-size:14px; color:#475569; margin:0 0 12px;
padding:12px 16px; background:#f8fafc; border-radius:8px;
border:1px solid #e2e8f0; line-height:1.6; }
.wtsteps-wrap .hint b { color:#1e293b; }
.wtsteps-wrap .hint .ibox { color:#2563eb; font-weight:700; }
.wtsteps-wrap .hint .jbox { color:#dc2626; font-weight:700; }
.wtsteps-wrap .hint .gbox { color:#059669; font-weight:700; }
.wtsteps-wrap .hint kbd { font-family:'SF Mono',Menlo,monospace;
background:#e2e8f0; padding:1px 6px; border-radius:4px; font-size:12px;
border:1px solid #cbd5e1; }
.wtsteps-wrap .panel.step1 .fm-pij,
.wtsteps-wrap .panel.step1 .fm-w {
padding:2px 6px; border-radius:3px;
transition:background 0.18s, color 0.18s;
}
.wtsteps-wrap .panel.step1:not(.hover-j) .fm-w {
background:#fde047; color:#1d4ed8; font-weight:800;
}
.wtsteps-wrap .panel.step1.hover-j .fm-pij {
background:#fecaca; color:#991b1b; font-weight:800;
}
`;
wrapper.appendChild(style);
// ── Controls ──
const sliderRow = document.createElement("div");
sliderRow.style.cssText = "display:flex;gap:22px;margin:0 0 12px;align-items:flex-end;flex-wrap:wrap;";
const SL = {
meanGI: createSlider("Mean GI (days)", 1.5, 7, 0.5, 3, "#7c3aed", "purple"),
sdGI: createSlider("SD GI (days)", 0.5, 2.5, 0.1, 1.2, "#7c3aed", "purple")
};
sliderRow.appendChild(SL.meanGI.el);
sliderRow.appendChild(SL.sdGI.el);
wrapper.appendChild(sliderRow);
const hint = document.createElement("div");
hint.className = "hint";
hint.innerHTML = `
<b>Panel 1</b>: <kbd>tap</kbd>/<kbd>click</kbd> a case to set <span class="ibox">i</span>; tap an earlier case to set <span class="jbox">j</span> (tap again to clear). On desktop, <kbd>hover</kbd> an earlier case for a transient preview. Arc labels show w while idle and p<sub>ij</sub> for the chosen pair.<br>
<b>Panel 2</b>: <kbd>tap</kbd>/<kbd>click</kbd> a case to set <span class="gbox">j</span>; tap a later case to isolate one p<sub>ij</sub> (tap again to unisolate). On desktop, <kbd>hover</kbd> a later case for a transient isolate.<br>
<b>Panel 3</b>: <kbd>tap</kbd>/<kbd>click</kbd> a case to share it as <span class="gbox">j</span> with Panel 2.
`;
wrapper.appendChild(hint);
// ── R_j label positioning helper ──
function applyLabelPos(textEl, c) {
let dx = 0, dy = NODE_R + 24, anchor = "middle";
if (c.total > 1) {
if (c.slot === 0) { dy = -(NODE_R + 12); }
else if (c.slot === c.total - 1) { dy = NODE_R + 24; }
else { dx = NODE_R + 14; dy = 5; anchor = "start"; }
}
textEl.setAttribute("dx", dx);
textEl.setAttribute("dy", dy);
textEl.setAttribute("text-anchor", anchor);
}
// ── Shared builder ──
function buildNetwork(svgSel, H, prefix, onClick, onHover) {
svgSel.append("defs").html(`
<filter id="${prefix}-sh" x="-40%" y="-40%" width="180%" height="180%">
<feDropShadow dx="0" dy="1" stdDeviation="1.4" flood-color="#0f172a" flood-opacity="0.14"/>
</filter>
<filter id="${prefix}-csh" x="-40%" y="-40%" width="180%" height="180%">
<feDropShadow dx="0" dy="0.6" stdDeviation="1" flood-color="#0f172a" flood-opacity="0.18"/>
</filter>
`);
const netG = svgSel.append("g");
for (let d = 1; d <= T; d++) {
const x = netM.left + (d - 1) * xSp;
netG.append("text")
.attr("x", x).attr("y", H - netM.bottom + 28)
.attr("text-anchor", "middle")
.style("font-size", "15px").style("font-weight", "600")
.style("fill", "#64748b").style("letter-spacing", "0.3px")
.text("Day " + d);
}
const arcG = netG.append("g");
const nodeG = netG.append("g");
const labelG = netG.append("g");
const arcPaths = pairs.map(p => {
const pi = nodePos(cases[p.i], H);
const pj = nodePos(cases[p.j], H);
const gap = cases[p.i].day - cases[p.j].day;
const g = arcGeom(pi, pj, gap);
const path = arcG.append("path")
.attr("d", g.d).attr("fill", "none")
.attr("stroke-linecap", "round").node();
return { path, px: g.px, py: g.py };
});
const nodes = cases.map((c, idx) => {
const pos = nodePos(c, H);
const grp = nodeG.append("g")
.attr("class", "node-grp")
.attr("transform", `translate(${pos.x}, ${pos.y})`);
const circle = grp.append("circle")
.attr("r", NODE_R)
.attr("fill", "#fff").attr("stroke", "#94a3b8").attr("stroke-width", 2)
.attr("filter", `url(#${prefix}-sh)`);
const text = grp.append("text")
.attr("text-anchor", "middle").attr("dy", 6)
.style("font-size", "18px").style("font-weight", "800")
.style("fill", "#475569").style("pointer-events", "none")
.text(c.id);
const below = grp.append("text")
.attr("text-anchor", "middle")
.attr("dy", NODE_R + 24)
.style("font-size", "15px").style("font-weight", "700")
.style("font-family", "'SF Mono',Menlo,monospace")
.style("pointer-events", "none")
.attr("opacity", 0);
const gNode = grp.node();
gNode.addEventListener("click", () => onClick(idx));
if (onHover) {
gNode.addEventListener("mouseenter", () => onHover(idx, true));
gNode.addEventListener("mouseleave", () => onHover(idx, false));
}
return { grp: gNode, circle: circle.node(), text: text.node(),
below: below.node(), pos };
});
const arcs = arcPaths.map((a) => {
const lgrp = labelG.append("g")
.attr("transform", `translate(${a.px}, ${a.py - 12})`)
.attr("opacity", 0);
const lrect = lgrp.append("rect")
.attr("x", -27).attr("y", -14)
.attr("width", 54).attr("height", 27)
.attr("rx", 5).attr("ry", 5)
.attr("fill", "#fff").attr("stroke-width", 1.3)
.attr("filter", `url(#${prefix}-csh)`);
const ltxt = lgrp.append("text")
.attr("text-anchor", "middle").attr("dy", 5)
.style("font-size", "15px").style("font-weight", "700")
.style("font-family", "'SF Mono',Menlo,monospace");
return { path: a.path, lgrp: lgrp.node(),
lrect: lrect.node(), ltxt: ltxt.node() };
});
const hdrG = netG.append("g").style("pointer-events", "none");
const mkHdr = () => {
const rect = hdrG.append("rect").attr("rx", 11).attr("ry", 11)
.attr("filter", `url(#${prefix}-csh)`).attr("opacity", 0).node();
const txt = hdrG.append("text").attr("text-anchor", "middle")
.style("font-size", "14px").style("font-weight", "800")
.style("letter-spacing", "0.6px").style("fill", "#fff")
.attr("opacity", 0).node();
return { rect, txt };
};
return { arcs, nodes, hdrI: mkHdr(), hdrJ: mkHdr() };
}
function setHdr(hdr, pos, label, color, side = "above") {
hdr.txt.textContent = label;
const tw = label.length * 8.2 + 22;
let yRect, yTxt;
if (side === "above") { yRect = pos.y - NODE_R - 38; yTxt = pos.y - NODE_R - 19; }
else { yRect = pos.y + NODE_R + 10; yTxt = pos.y + NODE_R + 29; }
hdr.rect.setAttribute("x", pos.x - tw / 2);
hdr.rect.setAttribute("y", yRect);
hdr.rect.setAttribute("width", tw);
hdr.rect.setAttribute("height", 28);
hdr.rect.setAttribute("fill", color);
hdr.txt.setAttribute("x", pos.x);
hdr.txt.setAttribute("y", yTxt);
hdr.rect.setAttribute("opacity", 1);
hdr.txt.setAttribute("opacity", 1);
}
function hdrSide(c) {
if (c.total === 1) return "above";
if (c.slot === 0) return "below";
if (c.slot === c.total - 1) return "above";
return "above";
}
function hideHdr(hdr) {
hdr.rect.setAttribute("opacity", 0);
hdr.txt.setAttribute("opacity", 0);
}
// ═══════════════════════════════════════════════════════════════════════
// Panel 1
// ═══════════════════════════════════════════════════════════════════════
const H1net = 360;
const H1gi = 180;
const H1 = H1net + H1gi;
const p1 = document.createElement("div");
p1.className = "panel step1";
p1.innerHTML = `
<div class="panel-head">
<span class="badge">Step 1</span>
<span class="pname">Attribution probabilities p<sub>ij</sub></span>
<span class="pformula"><span class="fm-pij">p<sub>ij</sub></span> = <span class="fm-w">w<sub>tᵢ−tⱼ</sub></span> / Σ<sub>k≠i</sub> w<sub>tᵢ−tₖ</sub></span>
</div>
`;
const p1Svg = d3.create("svg").attr("viewBox", `0 0 ${W} ${H1}`);
// Click rules (work on both desktop and mobile):
// • no i yet → clicked becomes i
// • click current i → drop j first; if no j, drop i too (full reset)
// • click earlier case → toggle selJ1 (lock / unlock j)
// • click later case → that becomes new i, j cleared
function onClickP1(cIdx) {
if (selI === null) { selI = cIdx; selJ1 = null; drawAll(); return; }
if (cIdx === selI) {
if (selJ1 !== null) selJ1 = null;
else selI = null;
drawAll(); return;
}
if (cases[cIdx].day < cases[selI].day) {
selJ1 = (selJ1 === cIdx) ? null : cIdx;
drawAll(); return;
}
selI = cIdx; selJ1 = null;
drawAll();
}
// Hover only fires on devices with hover capability; gives desktop users
// a transient preview that overrides the clicked selJ1 while the cursor is
// over the case. Mobile users rely on the click toggle above.
function onHoverP1(cIdx, entering) {
if (!entering) {
if (hoverJ === cIdx) hoverJ = null;
} else if (selI !== null && cIdx !== selI &&
cases[cIdx].day < cases[selI].day) {
hoverJ = cIdx;
} else {
hoverJ = null;
}
drawAll();
}
const p1Net = buildNetwork(p1Svg, H1net, "p1", onClickP1, onHoverP1);
// ── GI sub-panel ──
const giG = p1Svg.append("g").attr("transform", `translate(0, ${H1net})`);
giG.append("line")
.attr("x1", 54).attr("x2", W - 54)
.attr("y1", 4).attr("y2", 4)
.attr("stroke", "#e2e8f0").attr("stroke-width", 1);
giG.append("text")
.attr("x", 54).attr("y", 26)
.style("font-size", "15px").style("font-weight", "700").style("fill", "#1e293b")
.text("Generation interval wₛ");
giG.append("text")
.attr("x", 54).attr("y", 46)
.style("font-size", "13px").style("fill", "#64748b")
.text("weight for each day-gap s between infector and infectee");
const dReadout = giG.append("text")
.attr("x", W - 54).attr("y", 26)
.attr("text-anchor", "end")
.style("font-size", "15px").style("font-weight", "700")
.style("font-family", "'SF Mono',Menlo,monospace").style("fill", "#1d4ed8").node();
const pBg = giG.append("rect")
.attr("rx", 5).attr("ry", 5)
.attr("fill", "#fecaca")
.attr("opacity", 0).node();
const pReadout = giG.append("text")
.attr("x", W - 54).attr("y", 50)
.attr("text-anchor", "end")
.style("font-size", "15px").style("font-weight", "800")
.style("font-family", "'SF Mono',Menlo,monospace").style("fill", "#991b1b").node();
const giM = { top: 70, right: 54, bottom: 36, left: 54 };
const giPlotW = W - giM.left - giM.right;
const giPlotH = H1gi - giM.top - giM.bottom;
const giBarG = giG.append("g").attr("transform", `translate(${giM.left}, ${giM.top})`);
giBarG.append("line")
.attr("x1", 0).attr("x2", giPlotW).attr("y1", giPlotH).attr("y2", giPlotH)
.attr("stroke", "#cbd5e1").attr("stroke-width", 1);
const MAX_S = 6;
const giStep = giPlotW / MAX_S;
const giBars = [];
const giValLabels = [];
for (let s = 1; s <= MAX_S; s++) {
const bx = (s - 1) * giStep;
giBars.push(giBarG.append("rect")
.attr("x", bx + giStep * 0.18)
.attr("width", giStep * 0.64)
.attr("rx", 2).attr("ry", 2).node());
giValLabels.push(giBarG.append("text")
.attr("x", bx + giStep / 2)
.attr("text-anchor", "middle")
.style("font-size", "14px").style("font-weight", "700")
.style("font-family", "'SF Mono',Menlo,monospace").node());
giBarG.append("text").attr("x", bx + giStep / 2).attr("y", giPlotH + 22)
.attr("text-anchor", "middle")
.style("font-size", "15px").style("font-weight", "600")
.style("font-family", "'SF Mono',Menlo,monospace").style("fill", "#64748b")
.text("w" + subD(s));
}
p1.appendChild(p1Svg.node());
// ═══════════════════════════════════════════════════════════════════════
// Panel 2
// ═══════════════════════════════════════════════════════════════════════
const H2 = 360;
const p2 = document.createElement("div");
p2.className = "panel step2";
p2.innerHTML = `
<div class="panel-head">
<span class="badge">Step 2</span>
<span class="pname">Sum over i: R<sub>j</sub></span>
<span class="pformula">R<sub>j</sub> = Σ<sub>i</sub> p<sub>ij</sub></span>
</div>
`;
const p2Svg = d3.create("svg").attr("viewBox", `0 0 ${W} ${H2}`);
// Click rules:
// • click a case at/before j → that case becomes new j, isolation cleared
// • click a case after j → toggle stickI2 (isolate / unisolate that arc)
function onClickP2(cIdx) {
if (selJ2 !== null && cases[cIdx].day > cases[selJ2].day) {
stickI2 = (stickI2 === cIdx) ? null : cIdx;
} else {
selJ2 = cIdx; stickI2 = null;
}
drawAll();
}
function onHoverP2(cIdx, entering) {
if (!entering) {
if (hoverI2 === cIdx) hoverI2 = null;
} else if (selJ2 !== null && cIdx !== selJ2 &&
cases[cIdx].day > cases[selJ2].day) {
hoverI2 = cIdx;
} else {
hoverI2 = null;
}
drawAll();
}
const p2Net = buildNetwork(p2Svg, H2, "p2", onClickP2, onHoverP2);
p2.appendChild(p2Svg.node());
// ═══════════════════════════════════════════════════════════════════════
// Panel 3: layout height is H3plot; the SVG is H3 = H3plot + bottom band,
// so the R_t^c labels sit in dedicated space below the day ticks instead
// of being clipped at the SVG edge.
// ═══════════════════════════════════════════════════════════════════════
const H3plot = 380;
const H3bot = 12; // small band: Rₜᶜ sits ~13 px below the day ticks
const H3 = H3plot + H3bot;
const p3 = document.createElement("div");
p3.className = "panel step3";
p3.innerHTML = `
<div class="panel-head">
<span class="badge">Step 3</span>
<span class="pname">Average R<sub>j</sub> per day</span>
<span class="pformula">R<sub>t</sub><sup>c</sup> = 𝔼(R<sub>j</sub> | t<sub>j</sub> = t)</span>
</div>
`;
const p3Svg = d3.create("svg").attr("viewBox", `0 0 ${W} ${H3}`);
const dayBoxes = [];
for (let d = 1; d <= T; d++) {
const x = netM.left + (d - 1) * xSp;
const cnt = perDay[d - 1];
const yC = netM.top + (H3plot - netM.top - netM.bottom) / 2;
const maxOff = Math.max(...slotOffsets[cnt].map(Math.abs));
const boxH = 2 * (maxOff + NODE_R + 36);
const hasRight = cnt === 3;
const boxLeft = x - NODE_R - 16;
const boxRight = x + NODE_R + (hasRight ? 84 : 16);
dayBoxes.push(p3Svg.append("rect")
.attr("x", boxLeft).attr("y", yC - boxH / 2)
.attr("width", boxRight - boxLeft).attr("height", boxH)
.attr("rx", 12).attr("ry", 12)
.attr("fill", "#fffbeb").attr("stroke", "#f59e0b").attr("stroke-width", 1.5)
.attr("stroke-dasharray", "5,4").attr("opacity", 0.85).node());
}
const p3Net = buildNetwork(p3Svg, H3plot, "p3", (idx) => {
if (selJ2 !== idx) stickI2 = null;
selJ2 = idx;
drawAll();
});
const rtcLabels = [];
for (let d = 1; d <= T; d++) {
const x = netM.left + (d - 1) * xSp;
rtcLabels.push(p3Svg.append("text")
.attr("x", x).attr("y", H3 - 14)
.attr("text-anchor", "middle")
.style("font-size", "16px").style("font-weight", "800")
.style("font-family", "'SF Mono',Menlo,monospace").style("fill", "#b45309")
.node());
}
p3.appendChild(p3Svg.node());
// ── Colour palettes ──
const C1 = {
iFill:"#2563eb", iStroke:"#1d4ed8",
jFill:"#dc2626", jStroke:"#991b1b", jAccent:"#b91c1c",
pastFill:"#dbeafe", pastStroke:"#60a5fa", pastTxt:"#1e3a8a",
arcBlue:"#2563eb", arcRed:"#dc2626"
};
const C2 = {
jFill:"#059669", jStroke:"#065f46",
hoverFill:"#047857", hoverStroke:"#064e3b",
futFill:"#d1fae5", futStroke:"#34d399", futTxt:"#065f46",
arcGreen:"#059669", arcHover:"#064e3b"
};
// ═══════════════════════════════════════════════════════════════════════
// Draw
// ═══════════════════════════════════════════════════════════════════════
function drawPanel1() {
const iSet = selI !== null;
// Effective j: a fresh hover (desktop only) takes priority over the
// click-committed selJ1, which is sticky on both desktop and mobile.
const effJ = iSet ? (hoverJ !== null ? hoverJ : selJ1) : null;
const jSet = effJ !== null;
p1.classList.toggle("hover-j", jSet);
const di = iSet ? cases[selI].day : -1;
const D = iSet ? computeDenom(selI) : 0;
const gapJ = jSet ? di - cases[effJ].day : -1;
p1Net.nodes.forEach((n, idx) => {
const c = cases[idx];
let fill = "#fff", stroke = "#94a3b8", txt = "#475569";
if (idx === selI) { fill = C1.iFill; stroke = C1.iStroke; txt = "#fff"; }
else if (idx === effJ) { fill = C1.jFill; stroke = C1.jStroke; txt = "#fff"; }
else if (iSet && c.day < di) { fill = C1.pastFill; stroke = C1.pastStroke; txt = C1.pastTxt; }
n.circle.setAttribute("fill", fill);
n.circle.setAttribute("stroke", stroke);
n.circle.setAttribute("stroke-width", (idx === selI || idx === effJ) ? 3 : 2);
n.text.style.fill = txt;
n.grp.setAttribute("opacity", 1);
n.below.setAttribute("opacity", 0);
});
p1Net.arcs.forEach((a, k) => {
const p = pairs[k];
if (iSet && p.i === selI) {
const g = cases[p.i].day - cases[p.j].day;
const w = weights[g] || 0;
if (jSet && p.j === effJ) {
// Hover: proportional width, amplified over the non-hover scale
a.path.setAttribute("stroke", C1.arcRed);
a.path.setAttribute("stroke-width", Math.max(3.2, w * 42));
a.path.setAttribute("opacity", 1);
const pij = D > 0 ? w / D : 0;
a.ltxt.textContent = pij.toFixed(2);
a.ltxt.style.fill = C1.jAccent;
a.lrect.setAttribute("stroke", C1.jFill);
a.lrect.setAttribute("stroke-width", 2);
a.lgrp.setAttribute("opacity", 1);
} else {
a.path.setAttribute("stroke", C1.arcBlue);
a.path.setAttribute("stroke-width", Math.max(2, w * 28));
a.path.setAttribute("opacity", jSet ? 0.22 : 0.92);
a.ltxt.textContent = w.toFixed(2);
a.ltxt.style.fill = "#1d4ed8";
a.lrect.setAttribute("stroke", "#60a5fa");
a.lrect.setAttribute("stroke-width", 1.3);
a.lgrp.setAttribute("opacity", w > 0.005 ? (jSet ? 0.18 : 1) : 0);
}
} else {
a.path.setAttribute("stroke", "#cbd5e1");
a.path.setAttribute("stroke-width", 1);
a.path.setAttribute("opacity", 0.1);
a.lgrp.setAttribute("opacity", 0);
}
});
if (iSet) {
const pos = nodePos(cases[selI], H1net);
setHdr(p1Net.hdrI, pos, "CASE i = " + cases[selI].id, C1.iFill, hdrSide(cases[selI]));
} else hideHdr(p1Net.hdrI);
if (jSet) {
const pos = nodePos(cases[effJ], H1net);
setHdr(p1Net.hdrJ, pos, "CASE j = " + cases[effJ].id, C1.jFill, hdrSide(cases[effJ]));
} else hideHdr(p1Net.hdrJ);
// GI bars
let wMax = 0;
for (let s = 1; s <= MAX_S; s++) if (weights[s] > wMax) wMax = weights[s];
if (wMax <= 0) wMax = 1;
const gapsUsed = new Set();
if (iSet) {
for (let k = 0; k < N; k++) {
if (k === selI) continue;
const g = di - cases[k].day;
if (g > 0 && g <= MAX_S) gapsUsed.add(g);
}
}
for (let s = 1; s <= MAX_S; s++) {
const bar = giBars[s - 1];
const val = giValLabels[s - 1];
const w = weights[s] || 0;
const h = (w / wMax) * giPlotH;
bar.setAttribute("y", giPlotH - h);
bar.setAttribute("height", h);
let fill = "#e2e8f0", opacity = 1, valColor = "#94a3b8";
if (s === gapJ) { fill = C1.jFill; opacity = 1; valColor = C1.jAccent; }
else if (gapsUsed.has(s)) { fill = C1.arcBlue; opacity = 0.9; valColor = "#1d4ed8"; }
bar.setAttribute("fill", fill);
bar.setAttribute("opacity", opacity);
val.setAttribute("y", giPlotH - h - 6);
val.textContent = w > 0.005 ? w.toFixed(3) : "";
val.style.fill = valColor;
}
// Readouts
if (iSet) {
const counts = {};
for (let k = 0; k < N; k++) {
if (k === selI) continue;
const g = di - cases[k].day;
if (g > 0 && g <= SMAX) counts[g] = (counts[g] || 0) + 1;
}
const gs = Object.keys(counts).map(Number).sort((a, b) => a - b);
const parts = gs.map(g => counts[g] === 1 ? "w" + subD(g) : counts[g] + "·w" + subD(g));
dReadout.textContent = parts.length
? SUM_SYM + " = " + parts.join(" + ") + " = " + D.toFixed(3)
: SUM_SYM + " = 0 (case " + cases[selI].id + " has no past)";
if (jSet) {
const w = weights[gapJ] || 0;
const p = D > 0 ? w / D : 0;
pReadout.textContent = "pᵢⱼ = w" + subD(gapJ) + " / (" + SUM_SYM + ") = "
+ w.toFixed(3) + " / " + D.toFixed(3) + " = " + p.toFixed(3);
const tLen = pReadout.getComputedTextLength();
pBg.setAttribute("x", W - 54 - tLen - 12);
pBg.setAttribute("y", 34);
pBg.setAttribute("width", tLen + 24);
pBg.setAttribute("height", 26);
pBg.setAttribute("opacity", 1);
} else {
pReadout.textContent = "(tap or hover an earlier case to set j)";
pBg.setAttribute("opacity", 0);
}
} else {
dReadout.textContent = "";
pReadout.textContent = "";
pBg.setAttribute("opacity", 0);
}
}
function drawPanel2(Rjs) {
const selDay = cases[selJ2].day;
const Rj = Rjs[selJ2];
// Effective i to isolate: hover (desktop) wins; otherwise the
// click-committed stickI2 (sticky on desktop and mobile).
const effI = hoverI2 !== null ? hoverI2 : stickI2;
const anyHover = effI !== null;
p2Net.nodes.forEach((n, idx) => {
const c = cases[idx];
let fill = "#fff", stroke = "#94a3b8", txt = "#475569", op = 1;
if (idx === selJ2) { fill = C2.jFill; stroke = C2.jStroke; txt = "#fff"; }
else if (idx === effI) { fill = C2.hoverFill; stroke = C2.hoverStroke; txt = "#fff"; }
else if (c.day > selDay) { fill = C2.futFill; stroke = C2.futStroke; txt = C2.futTxt;
if (anyHover) op = 0.45; }
else { if (anyHover) op = 0.55; }
n.circle.setAttribute("fill", fill);
n.circle.setAttribute("stroke", stroke);
n.circle.setAttribute("stroke-width", (idx === selJ2 || idx === effI) ? 3 : 2);
n.text.style.fill = txt;
n.grp.setAttribute("opacity", op);
if (idx === selJ2) {
applyLabelPos(n.below, c);
n.below.textContent = "Rⱼ = " + Rj.toFixed(2);
n.below.style.fill = C2.jStroke;
n.below.setAttribute("opacity", 1);
} else {
n.below.setAttribute("opacity", 0);
}
});
p2Net.arcs.forEach((a, k) => {
const p = pairs[k];
if (p.j === selJ2) {
const pij = computePij(p.i, p.j);
const isHover = anyHover && p.i === effI;
// Hover stroke also proportional, amplified vs. p * 30 default
a.path.setAttribute("stroke", isHover ? C2.arcHover : C2.arcGreen);
a.path.setAttribute("stroke-width", isHover ? Math.max(3.2, pij * 44) : Math.max(2, pij * 30));
a.path.setAttribute("opacity", isHover ? 1 : (anyHover ? 0.16 : 0.92));
a.ltxt.textContent = pij.toFixed(2);
a.ltxt.style.fill = isHover ? C2.hoverStroke : C2.jStroke;
a.lrect.setAttribute("stroke", isHover ? C2.hoverFill : C2.futStroke);
a.lrect.setAttribute("stroke-width", isHover ? 2 : 1.3);
const labelOp = pij > 0.005
? (isHover ? 1 : (anyHover ? 0.12 : 1))
: 0;
a.lgrp.setAttribute("opacity", labelOp);
} else {
a.path.setAttribute("opacity", 0);
a.lgrp.setAttribute("opacity", 0);
}
});
setHdr(p2Net.hdrI, nodePos(cases[selJ2], H2), "CASE j = " + cases[selJ2].id, C2.jFill, hdrSide(cases[selJ2]));
if (effI !== null) {
setHdr(p2Net.hdrJ, nodePos(cases[effI], H2), "CASE i = " + cases[effI].id, C2.hoverFill, hdrSide(cases[effI]));
} else {
hideHdr(p2Net.hdrJ);
}
}
function drawPanel3(Rjs) {
const dayRt = new Array(T + 1).fill(0);
for (let d = 1; d <= T; d++) {
let s = 0, c = 0;
for (let j = 0; j < N; j++) if (cases[j].day === d) { s += Rjs[j]; c++; }
dayRt[d] = c > 0 ? s / c : 0;
}
p3Net.nodes.forEach((n, idx) => {
const c = cases[idx];
n.circle.setAttribute("fill", "#fffbeb");
n.circle.setAttribute("stroke", "#d97706");
n.circle.setAttribute("stroke-width", 2);
n.text.style.fill = "#92400e";
n.grp.setAttribute("opacity", 1);
applyLabelPos(n.below, c);
n.below.textContent = "Rⱼ=" + Rjs[idx].toFixed(2);
n.below.style.fill = "#92400e";
n.below.setAttribute("opacity", 0.95);
});
p3Net.arcs.forEach((a, k) => {
const p = pairs[k];
const pij = computePij(p.i, p.j);
a.path.setAttribute("stroke", "#f59e0b");
a.path.setAttribute("stroke-width", Math.max(0.5, pij * 10));
a.path.setAttribute("opacity", 0.22);
a.lgrp.setAttribute("opacity", 0);
});
hideHdr(p3Net.hdrI);
hideHdr(p3Net.hdrJ);
for (let d = 1; d <= T; d++) {
rtcLabels[d - 1].textContent = "Rₜᶜ = " + dayRt[d].toFixed(2);
}
}
function drawAll() {
updW(SL.meanGI.val(), SL.sdGI.val());
const Rjs = new Float64Array(N);
for (let j = 0; j < N; j++) Rjs[j] = computeRj(j);
drawPanel1();
drawPanel2(Rjs);
drawPanel3(Rjs);
}
SL.meanGI.input.addEventListener("input", () => { SL.meanGI.sync(); drawAll(); });
SL.sdGI .input.addEventListener("input", () => { SL.sdGI .sync(); drawAll(); });
wrapper.appendChild(p1);
wrapper.appendChild(p2);
wrapper.appendChild(p3);
drawAll();
return wrapper;
}